
티스토리 뷰
1. 워드(Word)
워드는 CPU가 한번에 처리하는 최대 크기의 Bit를 의미합니다.
16bit CPU 의 1word = 16bit = 2byte
32bit CPU 의 1word = 32bit = 4byte
64bit CPU 의 1word = 64bit = 8byte
(단, 64bit의 경우 32bit 하위호환성을 위해서 별도로 동작하기도 합니다)
2. Cache Line
Cache Line은 L1<->L2<->L3<->DRAM 간 Data를 주고받는 Data의 최소 크기를 의미합니다.
Cache Line의 정해진 Rule은 없지만, 경험적으로 8 Word가 Cache Miss를 최소화 하는 크기로 알려져 있습니다.
32bit CPU 의 Cache Line = 8word = 8*32bit = 8*4byte = 32byte
64bit CPU 의 Cache Line = 8word = 8*64bit = 8*8byte = 64byte
위 정보는 CPU-Z의 Cache 정보에서도 확인할 수 있습니다.

3. 가상메모리
Cpu는 Process마다 메모리 Table(=Page Table)을 별도로 가지고 있습니다. Process마다 독립적으로 가지고 있는 이 메모리를 가상메모리(Virtual Memory, 이하 줄여서 VM) 라고 합니다.
이 VM은 ALU와 레지스터 수준에서만 의미가 있고, 실제 캐시로 메모리 주소를 찾아갈때는 물리메모리(Physical Memory, 이하 PM)로 변환이 이뤄져야 합니다.
CPU(ALU + 레지스터){VA(Virtual Address)} <===== TLB(가상<ㅡ>물리 메모리 변환) =====> 캐시{PA(Physical Address)}
TLB(Translation Lookaside Buffer)는 VA<ㅡ>PA 고속변환을 위한 별도의 캐시라고 보면 됩니다.
(Page Table 중 일부를 TLB에 저장합니다)
4. Page Table
Page는 VA<ㅡ>PA 변환을 위한 Mapping Table 이라고 할 수 있습니다.
Page Table을 아래 예시와 같습니다.
-----------------------------------------------------------
Page No.(Index)|V(Valid) | D(Dirty) | R(Reference) | Physical page number
001 | 1 | 0 | 1 | 0x001484261923...
010 | 0 | 1 | 1 | 0x001484261933...
011 | 1 | 0 | 1 | 0x001484261943...
100 | | | |아키텍쳐마다 다르지만, 32bit 가상메모리 주소같은 경우
0~11 bit을 Page Offset으로, 12~31bit을 Virtual Page Number로 사용합니다.
그러면 Virtual Page Number에 해당하는 Physical Page Number를 찾고
Phsical Page Number + Page Offset을 합친 26bit의 PA를 생성합니다.
이 PA를 이용해서 실제 캐시 or 메모리 or HDD에 접근하게 됩니다.
(26bit인 이유는 위 예제가 64MB 메인메모리 기준이라 그렇습니다. 32bit CPU의 PA가 항상 26bit인건 아니에요)
※참고
TLB에 찾으려 했던 Page가 없을 경우 TLB Miss가 발생합니다.
이때 TLB를 Page Table에서 찾게되고, Page Table에도 없을 경우 Page Fault가 발생하게 됩니다.
이 경우 이제 메인메모리가 아니라, HDD/SSD에서 Page와 Data를 다시 가지고 와야하면
이 경우 Page Swap이 발생하게 됩니다.
==> 램이 부족하면 컴퓨터가 느려지는 이유(공간이 부족에서 Page Swap이 빈번하게 발생)
32bit CPU 기준으로 4KB의 Page를 사용할 경우
메모리 주소 전체의 크기 = 2^32
Page Table 하나가 커버하는 메모리 주소의 크기 = 2^12
Page Table의 가능한 개수 = 2^32 / 2^12 = 2^20
5. PA로 실제 Data찾기
이제 PA를 기반으로 Data를 찾습니다.
아래는 32bit CPU 예시입니다.

PA가 32bit인 시스템이라고 가정합니다.
PA 일부는 Index를, 일부는 Tag를 의미합니다.
이때 Index에 해당하는 곳에는 Cache Line만큼(8워드 = 32byte)의 Data가 존재합니다.
Index위치를 먼저 찾고, 이 Index가 Valid여부 와 Mapping Table의 Tag와 PA의 Tag가 일치하는지 확인합니다.
둘다 True라면 Cache에 있는 Data에서 offset위치에 해당하는 Data를 CPU로 전송하게 됩니다.
Hit이 아니면 Cache Miss가 발생하고 Data를 DRAM으로 찾으로 가게 됩니다.
6. Set Associativity
위에서 예제는 Index에 Cache Line만큼의 Data가 존재한다고 했습니다.
하지만 실제로를 Index 내에 Data의 양은 1개의 Cache Line으로 고정 된 것이 아닙니다.
(위 경우는 그저 한가지 예시입니다)
아래를 보시면 하나의 Index에 다수의 Cache Line이 들어갈 수 있는것을 볼 수 있습니다
(한개의 Cell이 1 Cache Line이라고 보시면 됩니다)

이때 Way의 개수만큼 Tag의 일치 여부와 Valid를 확인하는 작업을 진행해야 합니다.
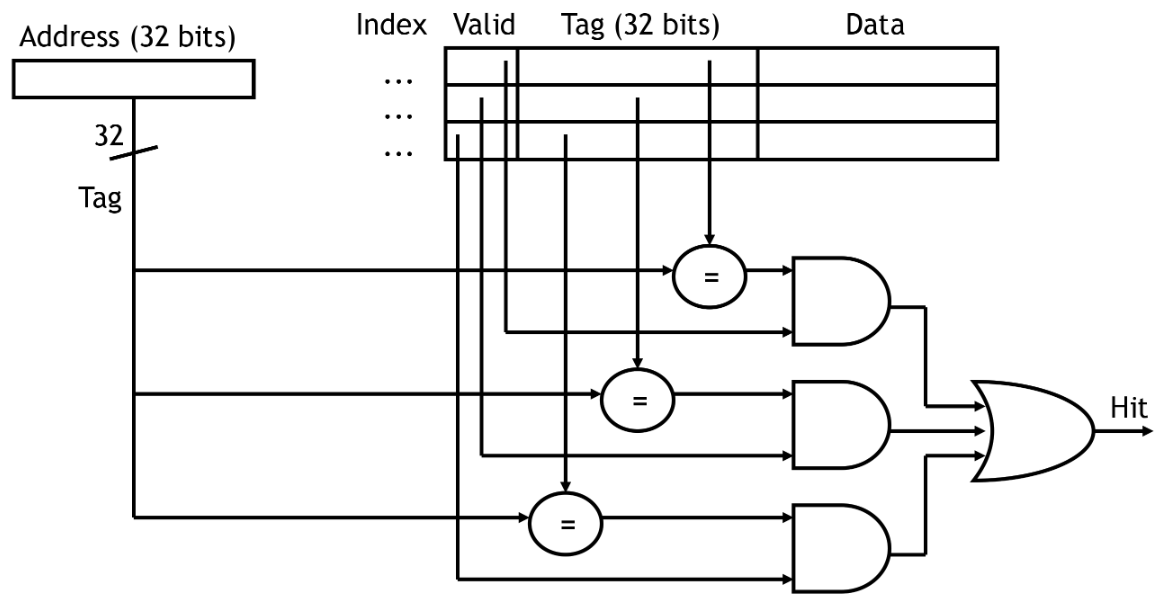
Way개수가 증가할 수록 장점은 보다 많은 메모리 주소를 효율적으로 활용이 가능합니다.
(Hash Table의 충돌을 생각하시면 쉽습니다.)
대신, 이 Way의 개수가 증가하면 그만큼 Data가 Cache에 있는지 확인하는데 시간이 증가합니다.
이러한 Cache Associativity의 정보는 Cpu-Z의 Cache 부분에서 역시 확인해 볼 수 있습니다.

- Total
- Today
- Yesterday
- prime number
- hash
- 병렬처리
- javascript
- Sort알고리즘
- 셀프모청
- 프로그래머스
- AVX
- SIMD
- 모바일청첩장
- Search알고리즘
- Python
- 코딩테스트
- 알고리즘
- 자료구조
- 동적계획법
- react
- 청첩장
- 완전탐색 알고리즘
- git
- Greedy알고리즘
- GPT
- stack
- ai
- 사칙연산
- GDC
- LLM
- 이분탐색
- ChatGPT
- 분할정복
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |